
Caching Demystified: From Theory to Production
Cache hits, Cache misses, update strategis, invalidation nightmares - everything you need to build fast, consistent, production grade caching systems.

There is an old joke in distributed systems: “There are only two hard things in computer science — cache invalidation and naming things.” Phil Karlton said it decades ago, and every engineer who has chased a stale-cache bug at 2 a.m. has silently agreed.
But caching is also one of the highest-leverage moves in a backend engineer’s toolkit. Done right, it can reduce database load by 80%, cut median latency from 120 ms to 4 ms, and let a $20/month VM serve traffic that would otherwise require a $2,000 database cluster.

What exactly is a cache?
A cache is a fast, temporary store that sits between your application and a slower data source, typically a database, an external API, or a compute-heavy function. When you ask for a piece of data, you check the cache first. If it’s there (cache hit), you return it immediately. If it’s not (cache miss), you fetch it from the source, store it in the cache, and return it.
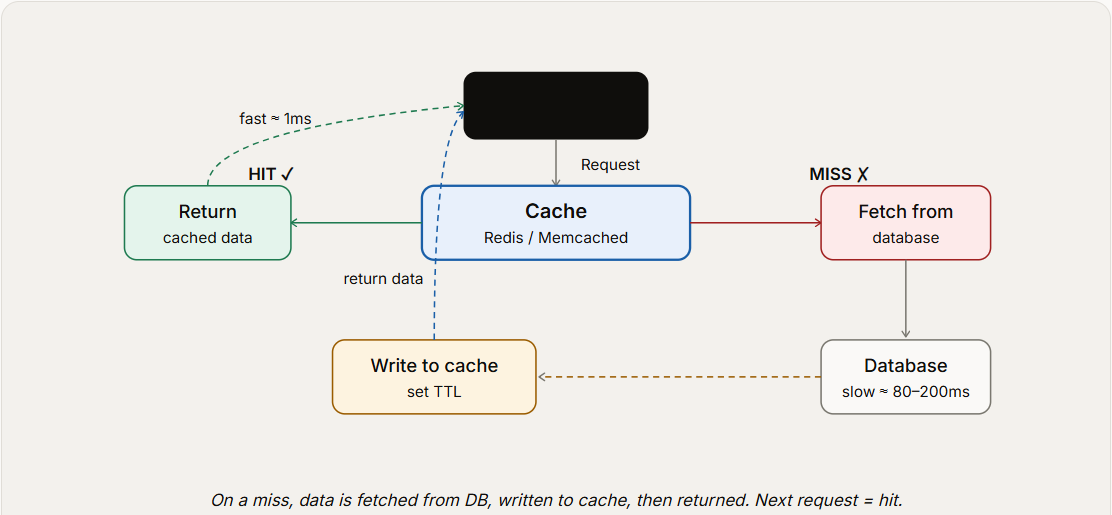
Figure 1 — Cache hit & miss flow. A hit returns in ~1 ms; a miss incurs the full database round-trip plus a write-through to populate the cache.
Checking the cache — the lookup pattern
Every cache interaction starts with a lookup. The lookup must be fast, non-blocking, and atomic.
Here’s the canonical pattern in Node.js with Redis, annotated for production:
// cache.service.ts - production-grade cache client
import { Redis } from ‘ioredis’;
const redis = new Redis
(
{
host: process.env.REDIS_HOST,
port: 6379,
maxRetriesPerRequest: 3,
enableReadyCheck: true,
lazyConnect: true,
connectTimeout: 5000,
}
);
async function getCached<T>
(
key: string,
fetchFn: () => Promise<T>,
ttlSeconds: number = 300
): Promise<T>
{
// 1. Try the cache first (O(1) lookup)
const cached = await redis.get(key);
if (cached !== null)
{
recordMetric(’cache.hit’, { key });
return JSON.parse(cached) as T;
}
// 2. Cache miss — fetch from source
recordMetric(’cache.miss’, { key });
const data = await fetchFn();
// 3. Populate cache asynchronously (don’t block the response)
redis
.setex(key, ttlSeconds, JSON.stringify(data))
.catch((err) => console.error(’Cache write failed:’, err));
return data;
}
// Usage
const user = await getCached(
`user:${userId}`,
() => db.findUserById(userId),
600 // 10 minutes
);Note: Key naming convention matters. Use a hierarchical namespace like
entity:id:field— e.g.user:42:profile. This lets you useSCANpatterns to invalidate entire entity groups without a full flush. Avoid generic keys likedataorresult.
Checking cache existence (without fetching value)
Sometimes you only need to know whether a key exists. For example, to check if a rate-limit counter is set, or if a job is already queued. Use EXISTS instead of GET: it returns 0 or 1 and costs less bandwidth.
import redis
r = redis.Redis(host=’localhost’, port=6379, decode_responses=True)
# Check existence without pulling the value
def is_rate_limited(user_id: str) -> bool:
key = f”ratelimit:{user_id}”
count = r.get(key)
if count is None:
# First request — set counter with 60s window
r.setex(key, 60, 1)
return False
if int(count) >= 100:
return True
# Atomic increment — safe under concurrent requests
r.incr(key)
return False
# Check TTL remaining (useful for debugging)
ttl = r.ttl(f”user:{user_id}:profile”)
# -2 = key doesn’t exist, -1 = no expiry, N = seconds remainingCache update strategies
This is where most engineers underestimate complexity. How you update the cache after data changes determines your consistency guarantees, your failure modes, and your operational burden. There are four mainstream patterns.

Figure 2 — The four cache update strategies and recommended use cases.
Strategy 1: Cache-aside (lazy loading) — the default
The application is responsible for all cache interactions. On a miss, it fetches from the database and populates the cache. This is the most prevalent strategy because it only caches data that is actually requested.
// ProductService with cache-aside + singleflight to prevent thundering herd
package service
import
(
“context”
“encoding/json”
“fmt”
“time”
“golang.org/x/sync/singleflight”
)
type ProductService struct
{
cache CacheClient
db DBClient
group singleflight.Group
}
func (s *ProductService) GetProduct(ctx context.Context, id string) (*Product, error)
{
key := fmt.Sprintf(”product:%s”, id)
// singleflight collapses concurrent misses into one DB call
v, err, _ := s.group.Do(key, func() (interface{}, error)
{
// 1. Check cache
if raw, err := s.cache.Get(ctx, key); err == nil
{
var p Product
json.Unmarshal([]byte(raw), &p)
return &p, nil
}
// 2. Cache miss — hit database
p, err := s.db.FindProduct(ctx, id)
if err != nil { return nil, err }
// 3. Write to cache (jitter prevents thundering herd on expiry)
ttl := 5*time.Minute + jitter(30*time.Second)
data, _ := json.Marshal(p)
s.cache.Set(ctx, key, data, ttl)
return p, nil
})
if err != nil { return nil, err }
return v.(*Product), nil
}Note: - When a popular cache key expires, hundreds of concurrent requests all miss simultaneously and hammer the database. The
singleflightpattern collapses all concurrent requests for the same key into a single database call, sharing the result with all waiters. Always use it in high-traffic services.
Strategy 2: Write-through — synchronous consistency
Every write updates both the cache and the database atomically. The write path is slower, but you never serve stale reads, ideal for financial balances, inventory counts, or user settings where correctness trumps latency.
async function updateUserBalance
(
userId: string,
newBalance: number
): Promise<void>
{
// Write-through: update DB and cache in a single logical operation
const pipeline = redis.pipeline();
await db.transaction(async (trx) =>
{
// 1. Update the source of truth
await trx.query
(
‘UPDATE accounts SET balance = ? WHERE id = ?’,
[newBalance, userId]
);
// 2. Invalidate the stale key (prefer invalidate over overwrite
// so we don’t cache uncommitted data if the transaction rolls back)
pipeline.del(`user:${userId}:balance`);
});
// Execute cache invalidation only after commit succeeds
await pipeline.exec();
}Note: If the transaction rolls back, you'll have a cache entry with data that was never persisted. Always invalidate (or update) the cache only after a successful database commit.
Strategy 3: Write-back (write-behind) — maximum write throughput
Writes go to the cache immediately; an asynchronous worker flushes dirty entries to the database in batches. Massively improves write throughput, at the cost of a window of potential data loss if the cache node fails before flushing.
import asyncio, json, redis.asyncio as aioredis
r = aioredis.Redis(host=’localhost’)
DIRTY_SET = “dirty:cart:keys”
async def update_cart(user_id: str, item_id: str, qty: int):
# 1. Write to cache immediately (fast — returns in <1ms)
key = f”cart:{user_id}”
await r.hset(key, item_id, qty)
# 2. Mark key as dirty for the flush worker
await r.sadd(DIRTY_SET, key)
async def flush_worker():
“”“Runs every 5 seconds; flushes dirty keys to Postgres.”“”
while True:
await asyncio.sleep(5)
dirty_keys = await r.smembers(DIRTY_SET)
for key in dirty_keys:
cart_data = await r.hgetall(key)
user_id = key.split(’:’)[1]
await db_upsert_cart(user_id, cart_data)
await r.srem(DIRTY_SET, key)Cache invalidation
The cache is just a liar you trust until you catch it. Invalidation is how you stop the lies.
There are three mechanisms for keeping cached data accurate: TTL-based expiry, explicit invalidation, and event-driven invalidation. Each has its place.

Figure 3 — Cache invalidation strategies. Most production systems combine TTL (safety net) with explicit invalidation (correctness).
Event-driven invalidation with CDC (Change Data Capture)
The most robust approach for microservice architectures: Debezium tails the Postgres WAL, publishes change events to Kafka, and a lightweight consumer deletes the relevant cache keys.
from kafka import KafkaConsumer
import json, redis
r = redis.Redis(host=’redis’)
consumer = KafkaConsumer
(
‘postgres.public.users’, # Debezium topic pattern
bootstrap_servers=[’kafka:9092’],
group_id=’cache-invalidator’,
auto_offset_reset=’latest’,
value_deserializer=lambda v: json.loads(v)
)
for msg in consumer:
event = msg.value
op = event[’op’] # ‘c’reate / ‘u’pdate / ‘d’elete
row = event.get(’after’) or event.get(’before’)
if op in (’u’, ‘d’) and row:
user_id = row[’id’]
# Delete all cache keys for this user
keys_to_invalidate =
[
f”user:{user_id}:profile”,
f”user:{user_id}:balance”,
f”user:{user_id}:permissions”,
]
if keys_to_invalidate:
r.delete(*keys_to_invalidate)
print(f”Invalidated {len(keys_to_invalidate)} keys for user {user_id}”)Production-grade patterns
Pattern 1: Cache stampede prevention with probabilistic early expiry
Instead of waiting for a key to expire before refreshing, probabilistically refresh it slightly before expiry based on how long the last fetch took. This eliminates the “everyone misses at exactly the same moment” problem without locking.
async function xfetch<T>
(
key: string,
fetchFn: () => Promise<T>,
ttl: number,
beta = 1
): Promise<T>
{
const raw = await redis.get(key);
if (raw)
{
const { value, expiry, delta } = JSON.parse(raw);
// Should we refresh early? Larger delta = more likely to refresh
const now = Date.now() / 1000;
if (now - delta * beta * Math.log(Math.random()) < expiry)
{
return value; // still “fresh enough”
}
}
const start = Date.now();
const value = await fetchFn();
const delta = (Date.now() - start) / 1000; // recompute time in seconds
const expiry = Date.now() / 1000 + ttl;
await redis.setex(key, ttl, JSON.stringify({ value, expiry, delta }));
return value;
}Pattern 2: Multi-tier caching (L1 in-process + L2 Redis)
For extreme read throughput, add an in-process L1 cache (e.g. LRU map with a 5-second TTL) in front of Redis. This can reduce Redis round-trips by 95% for the hottest keys — at the cost of brief per-instance inconsistency.
import LRU from ‘lru-cache’;
const l1 = new LRU<string, unknown>
(
{
max: 500,
ttl: 5_000, // 5-second in-process cache
}
);
async function tieredGet<T>(key: string, fetchFn: () => Promise<T>): Promise<T>
{
// L1: in-process (sub-millisecond)
const l1Hit = l1.get(key);
if (l1Hit !== undefined) return l1Hit as T;
// L2: Redis (1–3ms)
const l2Raw = await redis.get(key);
if (l2Raw)
{
const val = JSON.parse(l2Raw) as T;
l1.set(key, val); // populate L1
return val;
}
// L3: Database (50–200ms)
const data = await fetchFn();
await redis.setex(key, 300, JSON.stringify(data));
l1.set(key, data);
return data;
}Pattern 3: Negative caching — cache the misses
If your application frequently queries for records that don’t exist (user ID not found, promo code invalid), those misses hit the database every time. Cache a sentinel value with a short TTL to absorb the load.
Strategy comparison at a glance

Observability, metrics you must track
A cache you cannot observe is a liability. These are the non-negotiable metrics for any production caching layer:
1 Hit ratio —
hits / (hits + misses). Below 80% means your TTLs are too short, your key space is too wide, or you’re caching the wrong data. Target >95% for stable workloads.2 Latency percentiles — Track P50, P95, P99 for both cache hits and misses separately. Spikes in hit latency often reveal Redis memory pressure or network issues.
3 Memory usage & eviction rate — High eviction rates (
evicted_keysin RedisINFO stats) indicate your cache is undersized. Evictions destroy hit ratio and cause latency spikes.4 Key count & TTL distribution — Unexpectedly large key counts signal key leaks (no TTL set). Use
redis-cli --bigkeysandOBJECT ENCODINGto audit.5 Connection pool saturation — If your Redis client’s connection pool is full, requests queue and latency explodes. Monitor
connected_clientsand pool wait time.
# Overall stats (keyspace hits, misses, evictions)
redis-cli INFO stats | grep -E “keyspace|evicted|connected”
# Memory breakdown
redis-cli INFO memory | grep -E “used_memory_human|mem_fragmentation”
# Find largest keys (run during off-peak — scans all keys)
redis-cli --bigkeys
# Real-time command throughput
redis-cli --stat
# Keys expiring in the next 60 seconds (sampling)
redis-cli DEBUG SLEEP 0 && redis-cli INFO keyspaceCommon pitfalls and how to avoid them
Pitfall 1: Storing mutable objects by reference. Serialise everything to JSON before storing. If you cache a live object reference, mutations in the application code will silently corrupt the cached data and you won't know until a user reports stale behaviour.
Pitfall 2: No TTL on any key. Memory is finite. Every cached key must have a TTL, even if it’s 24 hours. Keys without TTL are permanent until explicitly deleted, and they will eventually fill your Redis instance and trigger evictions of hot data.
Pitfall 3: Caching non-serialisable data. Dates, Maps, Sets, class instances, and circular references don’t survive JSON serialisation. Use a schema (e.g. Zod or class-transformer) to serialise/deserialise cache values and catch these bugs in development.
Pitfall 4: Large objects in cache. Redis is not a blob store. Keep individual values under 1 MB. Large values increase serialisation overhead, consume memory disproportionately, and can block Redis’s single-threaded event loop on write. Compress with gzip for anything above 10 KB.
Pitfall 5: Cache as primary storage. Redis is ephemeral by default. Even with AOF/RDB persistence, treat it as a best-effort cache. Always have a database as the source of truth. If cache data must survive restarts, you need a different tool (e.g. Postgres with a fast index).
Caching is a spectrum. On one end: a simple SETEX wrapping your most expensive SQL query with a five-minute TTL. On the other end: a multi-tier, CDC-driven, probabilistically refreshed cache layer with per-key observability and automated eviction tuning. Most production systems live somewhere in the middle and that’s exactly right.
Start with cache-aside and a sensible TTL. Measure your hit ratio. Add explicit invalidation where staleness causes real pain. Only then reach for event-driven invalidation or write-back. Complexity should be earned by evidence, not assumed upfront.
The goal is not a perfect cache. The goal is a predictably fast system with clear failure modes that your on-call engineer can debug at 2 a.m. without a Ph.D. in distributed systems.